Abstract
MS사에서 진행한 연구. 자연어 처리에서의 중요한 패러다임 중 하나는 일반적인 도메인에서 학습된 대규모 사전학습 모델을 특정 과업이나 도메인에 적용시키는 것이다. 이 작업을 fine tuning이라고 하는데 더 큰 사전학습 모델을 사용할수록 모델의 매개변수를 유지하는 것은 더욱 어려워진다. 이는 더 많은 컴퓨팅 파워를 요구하고, 더 많은 비용을 야기하므로 현재 패러다임에서 큰 모델을 효과적으로 fine tuning 하는 방법을 찾는 것은 중요하다.
이에 연구진은 Low Rank Adaption (LoRA)를 제안한다. LoRA는 사전학습 모델의 가중치를 freeze하고 학습 가능한 rank decomposition matrices를 각 레이어에 끼워넣는 방식이다. 이는 downstream 작업에서 학습 가능한 매개변수의 개수를 크게 줄일 수 있다.
연구진이 예시로 든 GPT-3 175B 모델은 매개변수가 175 Billion 개라는 의미로 수많은 매개변수가 모델 안에 내재되어있음을 이름으로 알 수 있다. 해당 모델을 비롯하여 현재의 LLM 모델들은 billion 단위의 매개변수를 기본적으로 탑재하고 있고 이는 자연히 막대한 컴퓨팅 자원을 필요로 하게 된다.
예시 모델을 LoRA와 Adam으로 fine tuning한 경우 학습 가능한 매개변수는 10,000배 줄어들고 GPU memory 크기는 3배 줄어들게 된다. LoRA는 fine tuning된 RoBERTa, DeBERTa, GPT-2, GPT-3의 능력 동급 혹은 그 이상으로 기능한다. 더 적은 개수의 학습 가능 매개변수를 가졌음에도 불구하고 더 많은 학습 처리량을 보이며, adapter와는 다르게 추론 지연(inference latency)이 일어나지 않는다는 장점이 있다.
연구진은 또한 경험적 조사를 통해 language model adaptation의 낮은 계수(rank of matrix)가 모델의 효과를 조명함을 알아냈다.
이에 연구진은 RoBERTa, DeBERTa, GPT-2의 checkpoints와 LoRA를 PyTorch로 구현한 통합 구현체를 배포한다. : https://github.com/microsoft/LoRA
fine tuning은 새로운 데이터로 모델을 학습하여 일반적인 과제를 수행하는 대형 모델을 특수한 도메인에 정착시키는 과정이다. 이 과정은 단순 학습인데 왜 최적화 함수가 필요한가? 이전에 사용했던 최적화 함수를 다시 사용하면 되지 않나?
fine tuning도 결과적으로 ’학습’을 하는 과정이다. 학습 과정에서 optimizer는 최적화 함수로 loss function의 값이 가장 작은 값으로 수렴하도록 돕는 역할을 한다. 즉, loss function을 최적화하는 것이 optimizer의 목표다. optimizer 함수는 모델의 매개변수(parameter)를 매번 조절하여 손실함수의 값을 최소화하는데, 이를 통해 fine tuning에서도 tuning이 제대로 되고 있는지 확인할 수 있다. 최적화는 모델 성능에도 영향을 미치므로 단순히 이전에 사용했던 최적화 함수를 재사용하기보다는 새로운 전략을 모색하는 것이 효과적이다. 최적화 전략은 데이터셋의 크기, 사용 가능한 계산 리소스를 포함한 여러가지 요소를 고려하기 때문이다.
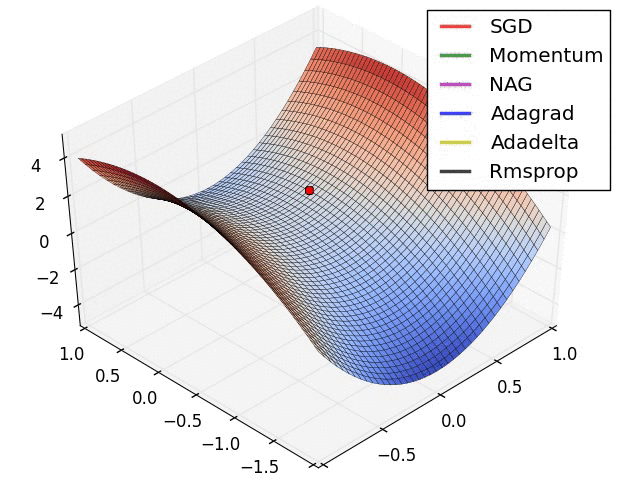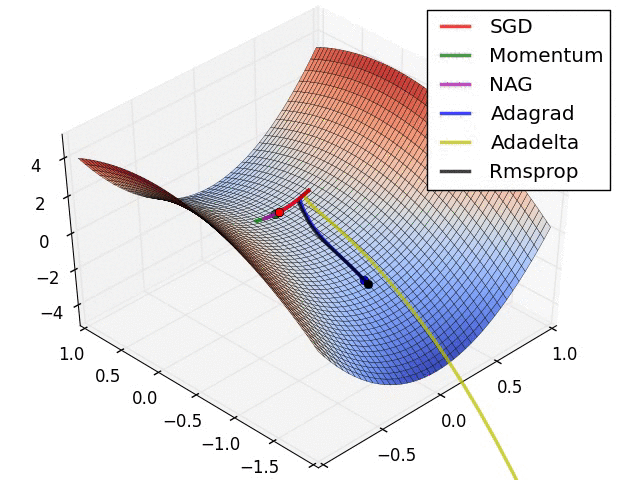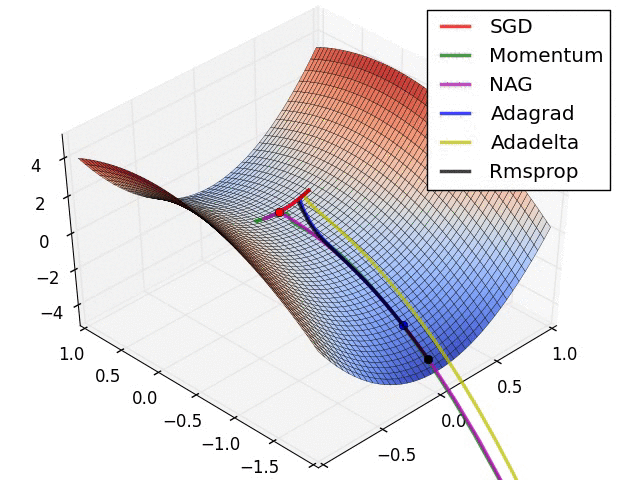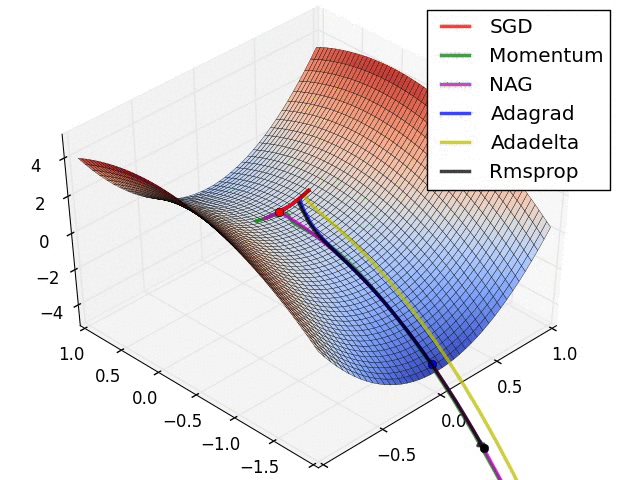 |
|---|
| optimization process |