LoRA
사전 학습된 모델 가중치를 동결하고 학습 가능한 순위 분해 행렬을 트랜스포머 아키텍처의 각 계층에 주입함으로써 LLM이 제기하는 비용 및 효율성 문제에 대한 해결책을 제시한다. 이 혁신적인 접근 방식은 다운스트림 작업에서 학습 가능한 파라미터의 수를 획기적으로 줄여 GPU 메모리 요구 사항을 크게 줄이고 학습 처리량을 개선한다. 여기서 ’Low Rank matrix’는 왜 중요할까? ’extensive deep learning model’의 가중치 행렬이 low rank matrix에 존재한다는 연구결과가 있었기 때문이다.
e.g. 1000차원의 임베딩 벡터가 있다고 하자. 이렇게 하면 \(1000x1000\) 차원의 K, Q, V 행렬이 생성되며, 각각 \(10^3 * 10^3 = 10^6\) 개의 훈련 가능한 파라미터가 생성된다. 반면 이를 low rank matrix로 압축시키면 학습 가능한 파라미터는 20000개로 줄어든다. 따라서 LLM의 목표는 이 행렬들을 low rank로 압축하여 학습해야하는 파라미터의 수를 줄이는 것이다. (그림 참고)
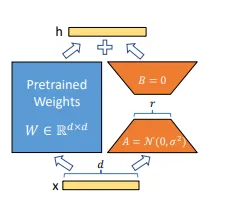
Our reparametrization. We only train A and B. For above example r=8 and d =1000. LLM에서의 fine tuning은 모델 내의 모든 가중치 행렬을 또 다른 가중치 행렬로 이동하는 과정으로 이해될 수 있는데 base model의 안정성을 위해 가중치행렬을 동결하고 (freeze) \(W\) 행렬을 두개의 low rank matrix인 \(A\), \(B\) 로 분해하는 과정을 거친다. 이 과정에서 가중치 행렬을 정확하게 찾아낼 수 있다면 좋겠지만 찾아내는 과정 또한 연산량에 포함된다. 그러므로
r파라미터로 가중치 행렬이 있을만한 ’적당히 작은 랭크의 행렬’으로 정하고 근사화한다. (LoRA)
Implementation
from peft import PeftModel
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, set_peft_model_state_dict
model = AutoModelForCausalLM.from_pretrained(
"bigcode/starcoder",
use_auth_token=True,
device_map={"": Accelerator().process_index},
)
# lora hyperparameters
lora_config = LoraConfig(r=8,target_modules = ["c_proj", "c_attn", "q_attn"])
model = get_peft_model(model, lora_config)
training_args = TrainingArguments(
...
)
trainer = Trainer(model=model, args=training_args,
train_dataset=train_data, eval_dataset=val_data)
print("Training...")
trainer.train()
# plugging the adapter into basemodel back
model = PeftModel.from_pretrained("bigcode/starcoder", peft_model_path)