목표
1. 이해할 수 있는데까지 이해하기
2. 코드를 이용한 재구현
- General Terms: Image Segmenatation
- Keywords: Image Segmentation, Vision Transformer, Swin Transformer, UNETR, Swin UNETR, BRATS, Brain Tumor Segmentation
Abstract
뇌종양의 semantic segmentation1은 근본적으로 multiple MRI imaging을 이용한 의료이미지 분석 과제다.
3D 의료 영상 세그멘테이션에서는 FCNNs 2 방식이 사실상의 표준 3으로 자리잡았다.
- U-Net: Convolutional Networks for Biomedical Image Segmentation 에서 발표되었으며 네트워크의 크기가 U모양이다.4
U-net은 다음 과제에서 SOTA를 달성했다.- 2D semantic segmentation
- 3D semantic segmentation
- across various imaging modalities
U-net의 한계는 이러하다: long range dependency- 반면 transformer 계열 모델에서는 long range 문제가 희박하게 일어나고, 이것을 medical domain에 적용한 것이
Swin UNEt TRansformers다.
UNETR 에서는 FCNNs이 아닌 tranformer를 적용했다.
- UNETR의 특징 또는 기여점
- 3D brain tumor semantic segmentation task를 seq2seq 과제로 재구성했다
- multi model 입력 데이터를 1D sequence에 embedding 했다.
- 해당 데이터를 계층적 UNETR의 인코더에 입력으로 사용했다.
- encoder: 5개의 다른 해상도의 특징 추출8 >> decoder: FCNN기반, 해상도 특징이 각각 연결된다. (via skip connection)
- UNETR의 특징 또는 기여점
2 Fully Convolutional Neural Networks
3 de facto standard
4 the expansive path is more or less symmetric to the contracting path, and yields a u-shaped architecture
5 이후 맥락에 따라 kernel크기에 따라 이미지 크기가 작아지는 문제로 보인다.
6 long-range information is sub-optimal
7 멀리 떨어질수록 관계가 줄어드는 지역적 특성을 살린 것이 CNN이다. 이게 다양한 크기의 종양 판별과 무슨 관계가 있는지 확인 필요.
8 각각 다른 해상도가 시사하는 바는?
Background
Region Proposal Network에서 언급하는 ’CNN으로 공간 정보를 보존한다’는 말이 이 말이다. 같은 segmentation task이니 모두 공간 정보를 보존하는게 중요할거라고 생각했는데 이 아이디어를 object detection에서 모두 쓰고 있었다. 초기 FCN의 segmentation이 얼마나 거칠었는지 생각해보면 큰 발전을 이뤘다고 할 수 있다.
| FCN (2015) | mask r-cnn (2018) |
| faster r-cnn (2016) | mask r-cnn (2018) |
발상: 이미지의 정보가 압축된 Feature map이 있다면 역으로 사용/복원할 수 있지 않을까?
| Fully Convolution Network |
CNN을 생각해보자. CNN은 이미지의 픽셀들에 Convolution 연산을 해서 특징들을 찾아낸다. 그걸 Feature map 이라고 했다. 그렇다면 어떤 모델이든 마지막 Convolution 레이어의 결과물, 다시 말해 마지막 Feature map 은 이미지의 특징을 가장 압축적으로 가지고 있는 행렬 아니겠나? 이걸 천천히 되돌려 생각하면 레이어마다 산출되는 Feature map 은 이미지의 정보를 \(n\) 배 압축한 행렬이 된다. 우리는 이렇게 이미지의 정보를 압축하는 과정을 down sampling 이라고 하기로 했다.
우리에겐 학습 과정이 있으니 down sampling 을 역으로 되짚어 갈 수도 있다. 이를 deconvolution 또는 up sampling의 한 종류라고 한다. 물론 다른 방법으로도 이미지를 복원할 수 있다. 그 방법을 논문에선 bilinear interpolation(이중선형보간)이라고 하는데, 선형 보간을 2차원으로 확장했다고 생각하면 될 것 같다. 픽셀간의 거리비를 이용해 빈 공간을 채우는 방식이라고 한다.
 |
 |
|---|---|
| linear interpolation | bilinear interpolation |
그러면 convolution은 어떻게 역으로 되짚어 가야할까? feature map의 크기를 키우면 된다. 우리는 feature map의 특정 픽셀에 해당하는 이미지의 픽셀들을 알고 있다. 그 이미지의 픽셀들을 convolution 한 결과가 feature map 이니 당연하다. 그리고 특징을 뽑아내는 과정에서 버렸던 정보들은 feature map에 kernel을 곱하면 된다. 나누기의 반대는 곱하기라는 개념과 크게 다르지 않다.
 |
 |
|---|---|
| convolution | deconvolution |
FCN에서는 이 두가지 개념에 skip architecture라는 고유한 구조를 적용해 모든 레이어를 컨볼루션화 한다. 참고로 논문에서 사용한 커널의 크기는 \(14 \times 14\)다.
- 가장 먼저 마지막 계층에 21채널의 \(1 \times 1\) convolution 레이어를 붙이는데 이는 PASCAL 이라는 객체 검출 데이터셋과 형태를 맞추기 위함이었다.
- 32x9 upsample로 시작한다. \(1 \times 1\) 형태의 pool5 layer를 32배 하는데 이때 upsample이 deconvolution 과정을 말한다. 이렇게 upsample 한 예측결과는 그대로 둔다.
- 16x upsample을 만든다.
- 마지막 layer(pool5)의 마지막 conv layer를 2배 upsample 하고 이를 커널(\(14 \times 14\))과 곱한다
- 직전 layer(pool4)을 1에 더하여 semantic 정보를 구체화 한다.
- 3에서 얻은 행렬을 16배 upsample 하여 pool4만 upsample 하는 것보다 세밀한 결과를 얻는다.
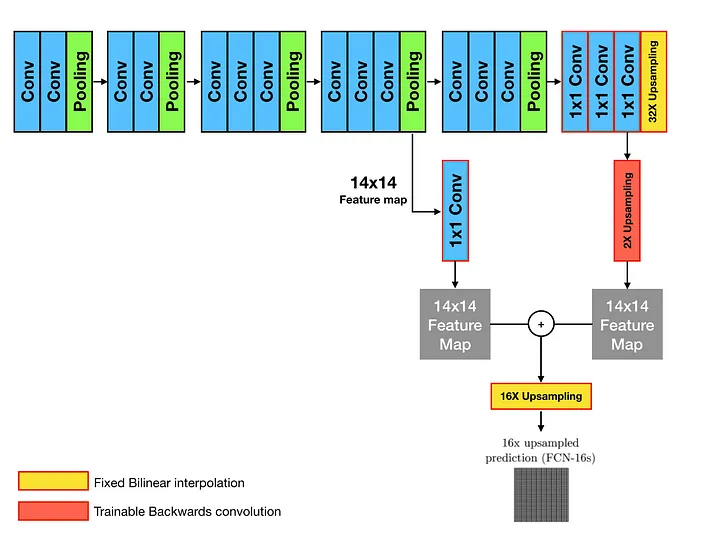 |
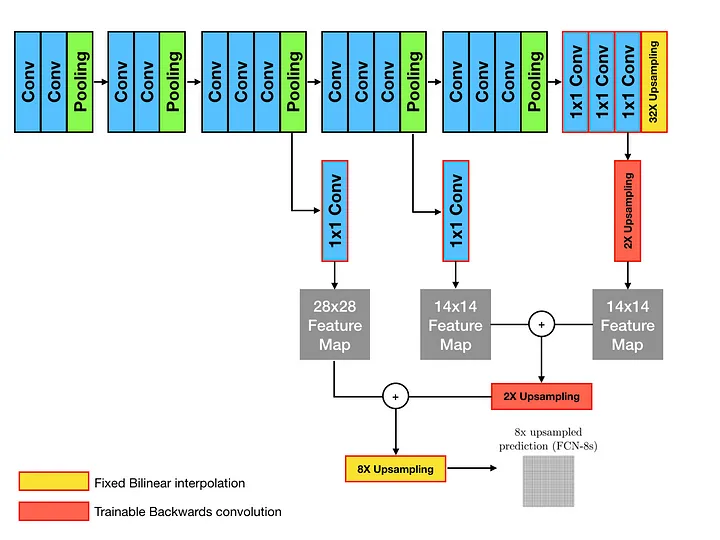 |
|
|---|---|---|
| FCN 16s | FCN 8s | DAG nets learn to combine coarse |
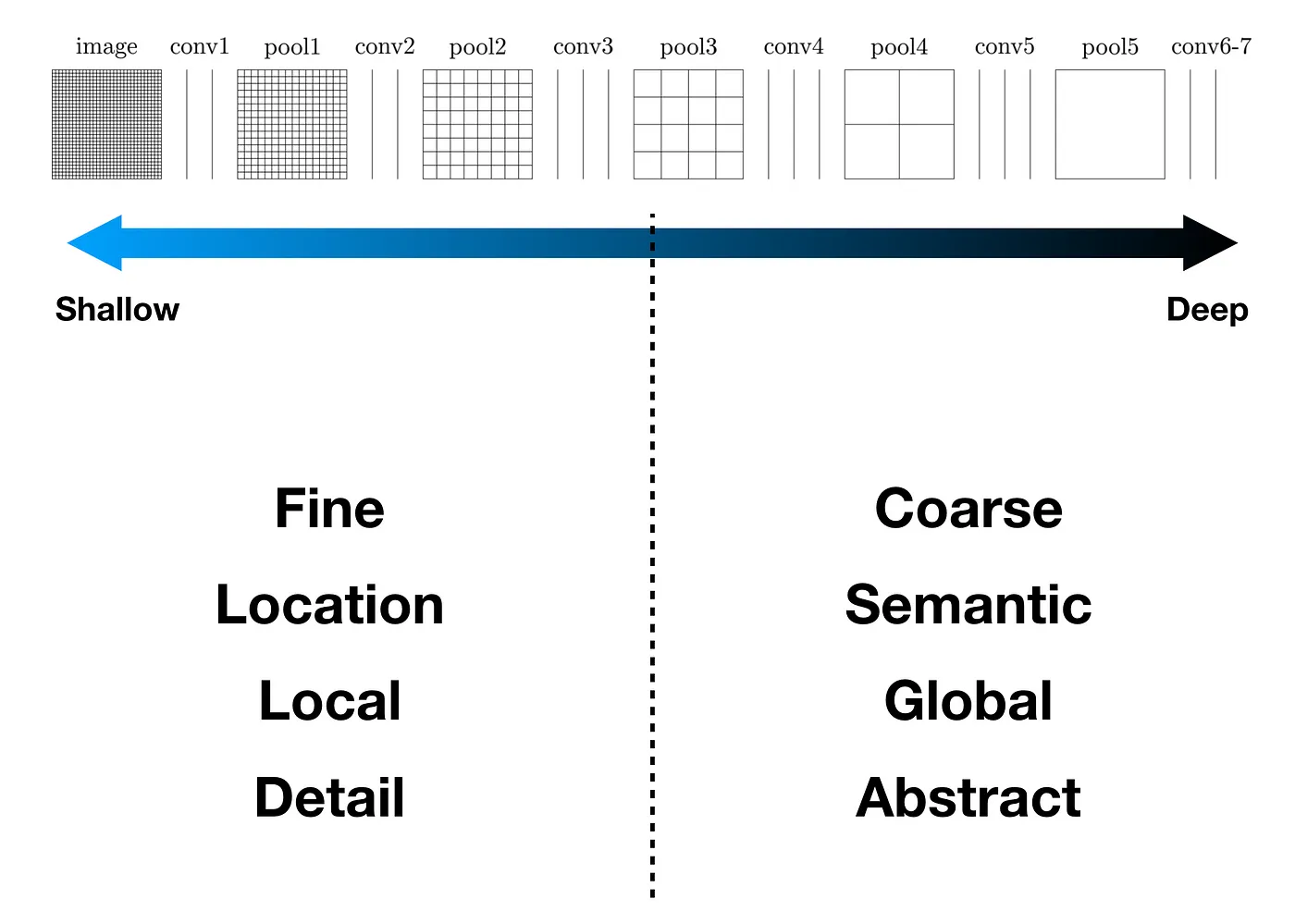
비슷한 과정을 8배에서도 진행해서 더 선명한 이미지를 얻고, 그렇게 복원된 이미지의 각 픽셀을 분류 하는 것이 segmentation의 전체 과정이다. 이때 해당 논문만의 특징인 skip architecture는 간단하게 각 feature map이 어떤 정보를 담고 있었을지 추론하는 과정을 생각해보면 된다. Convolution을 진행할수록 구체적인 정보보다는 대략적인 정보를 담게 되는데 이것에 착안해 후반의 layer에서는 대략적인 특성을, 초반의 layer에서는 구체적인 특성에 집중하도록 했다.
| FCN for segmentation | FCN layers |
 |
|---|
| skip architecture |
- 출처
- FCN: https://medium.com/@msmapark2
- bilinear interpolation: https://dambaekday.tistory.com/3
- deconvolution: https://realblack0.github.io/2020/05/11/transpose-convolution.html
9 stride 값이 32다. 16, 8 도 마찬가지다.
Introduction
- 인간 뇌에 영향을 미치는 brain tumors 는 120종류가 넘는다.
- 뇌종양은 두가지로 분류되는데10 원발성 뇌종양은 뇌에서 직접 발현하며11 이차성/전이성 뇌종양은 다른 장기로부터 전이된다.12
- 종양의 병리학적 단계에 따른 하위 분류: low grade gliomas(LGG)15, High grade gliomas(HGG)16
- HGG: 악성17으로 빠르게 자라며 수술 또는 방사선 치료가 필요한 종양, 예후가 좋지 않다.
- 참고: 분당서울대병원
- Magnetic Resonance Imaging (MRI)는 진단분석 도구로 쓰이며 모니터링, 분석, 수술계획 수립 등에서 사용된다.
- 딥러닝 기반 이미지 분할(image segmentation) 기법은 (1) 정확하고 (2) 재현 가능한 방법18을 제공하는데 두각을 드러낸다.
- CNN의 limited kernel size로 인한 long range dependencies 문제는 정확한 종양 segmentation에서 치명적이다; 종양이 다양한 크기나 모양으로 나타나기 때문
- 본 논문에서 주목한 ViT의 장점
- pairwise interaction between token embedding and its global contextual representation
- self-attention을 기반으로 한 transformer이므로 당연함
- effective learning of pretext task for self-supervised pre-training
- pretext task?
- SSL을 할때 연구자가 미리 설정해두는 과제로 모델은 해당 과제(task)를 목표로 라벨이 없는 데이터를 학습한다.
- 한 파트 안에서 다른 파트를 예측하는 학습인 self prediction과 배치 데이터 샘플 간의 유사성을 찾는 contrastive learning19으로 나뉜다. (출처)
- 자기지도학습에서 데이터의 표현을 학습하기 위해 구성한 문제를 pretext task라고 지칭하고, 실제로 풀고 싶은 문제를 downstream task라고 한다. ‘의료 데이터의 자기지도학습 적용을 위한 pretext task 분석’(공희산 외, 2021)은 rotation task와 jigsaw task를 수행했을때 이미지 전체를 보고 학습하는 rotation task의 효과가 더 좋았다고 발표했다.
- self-supervised(자기지도학습)이 논문의 과제에서 주요한 영향을 미치는 이유?
- pretext task?
- pairwise interaction between token embedding and its global contextual representation
- 의료 영상 분야에서 UNETR은 ViT를 encoder에 적용한 최초의 모델이다.
- Transformer와 Swin Transformer의 차이점?
- 우선 ‘Swin transformers are suitable for various down- stream tasks wherein the extracted multi-scale features can be leveraged for further processing.’ 때문에 사용했다고 한다.
- 종합적으로 Swin UNETR은 다음 세가지의 조합이 되겠다.
- Swin Transformer as an encoder
- utilized U-shape network
- CNN based decoder
10 Brain tumors are categorized into primary and secondary tumor types
11 primary tumor type originate from brain cells
12 secondary tumors metastasize into the brain from other organs
13 glial cell
14 gliomas
15 WHO grade II
16 WHO grade III-IV
17 malignant
18 재현 가능한 방법이 중요하게 언급 된 이유는 수술 때문인가?
19 siamese network를 기반으로 발전함
Swin UNETR
Encoder
입력
- \(\mathbb{R}^{H \times W \times D \times S}\) 형태, 이때 \(S\)는 샘플의 개수
- 해상도는 \(H',W',D'\), 차원은 \(H \times W \times D \times S\)
- 3D 입력을 균등하게 partition 하며 분해되어 만들어진 토큰의 크기는 레이어 \(l\) 을 지날수록 작아짐
- shifted window: \(M \times M \times M\)
- 다음 과정: \([\frac{H}{M'}] \times [\frac{W}{M'}] \times [\frac{D}{M'}]\)
- 분할된 토큰은 embedding space \(C\)로 투영된다. 20
- 연산의 효율성을 위해 non-overlapping windows 연산을 한다. (Swin Transformer의 원리)
20 embedding space
| 입력과정 |
ViT는 모든 patch 사이에 self attention 을 수행하나 몇가지 단점이 있다. 그 중 segmentation task와 관계있는 특징은 해상도21다. 자연어처리에서 transformer가 주로 풀었던 문제는 텍스트로, 이미지의 픽셀처럼 최소 단위의 세밀함을 필요로 하지 않는다. 하지만 이미지처리의 semantic segmentation 등 픽셀 단위에서의 조밀한 예측을 필요로 하는 task에서는 높은 해상도의 이미지가 필요하다. 그러나 self attention에 의해 컴퓨터의 연산량은 이미지 크기의 배로 늘어난다.22
22 Attention is all you need, 2017
21 Another difference is the much higher resolution of pixels in images compared to words in passages of text.
local window로 기존 ViT의 문제였던 time complexity를 줄이고, shifted window를 통한 patch merging으로 hierarchical architecture을 세운다. 그 결과 semantic segmentation이 가능해졌다.
| local window | patch merging |
|---|---|
이미지와 같이 작은 패치들이 모델이 깊어질수록 병합되는 구조다. 이런 hierarchical-representation 이 조밀한 예측을 가능하게 하여 피라미드 구조의 네트워크인 FPN(Feature Pyramid Network), U-Net 등에서 backbone으로 편리하게 사용할 수 있다. |
Swin Transformer의 핵심인 Shifted Window는 Fig 2와 같다. 빨간색의 window 안에서 패치간 self-attention을 계산하여 병합한 후 인접한 window에서 또다시 attention을 계산하여 관계가 있을 경우 병합하는 방식이다. |
Decoder
간단하게 Swin Transformer 과정에서 연산해두었던 각 단계의 feature map 과 그 단계에 해당하는 upsampling 과정의 데이터를 합산하여 해상도를 매 단계 당 두배씩 향상시킨다. 후에 \(1 \times 1 \times 1\) convolution layer를 통과시킨 후 sigmoid 함수를 활성화 함수로 사용했다.
Architecture
| Architecture |
- W-MSA: Window Multi-head self Attention
- SW-MSA: Shifted Window Multi-head self Attention
- 형태에 맞게 데이터를 입력한다.
- shift window 방법을 이용해 연관있는 patch끼리 병합하는 과정을 거친다.
- 계층적 구조를 유지하기 위해 merging layer에서 해상도가 2배23씩 낮아진다.
- Swin Transformer block을 통과한 결과를 embedding space \(C\)에 넘긴다.
- upsampling 해 해상도를 높인다.
- deconvolution을 통해 해상도가 두배씩 늘어난다.
- 인코딩 과정에서 연산한 feature를 skip connection을 통해 디코더로 전달한다.
- 원상복귀된 voxel을 얻는다.
23 factor of two
구현 후에 보충
참고
- Swin Transformer