focused and reviewed
- mainstream deep learning architectures
- single modalities
- multiple modalities for enhanced HAR
- DATA : short trimmed video segments
- one, only action instance
- Benchmark Datasets
Contribution follows
- various data modalities
- multi-modality based HAR
- approach 1: fusion based
- approach 2: cross modality co-learning-based
- recent, advanced methods: SOTA approaches
- comprehensive comparison of existing method
1. introduction
다양한 data modalities들의 장점, 한계를 및 modality간의 연구 흐름 파악
기술의 발전과 방법론의 창안은 선행 연구의 한계와 발전 가능성에 기초하므로 기술 발전의 흐름과 맥락을 숙지하는 과정은 중요하다. 본 논문은 2022 IEEE에 발표된 Review 논문으로 다양한 인간 행동 표현형을 인식하는 HAR 연구의 최신 흐름을 기술하고 있다. 개요에 따르면 인간 행동은 다양한 데이터 양식으로 표현될 수 있다. 데이터 양식은 크게 가시성 visibility 에 따라 visual modalities, non-visual modalities 로 나뉜다.
| visual modalities | non-visual modalities |
|---|---|
| RGB | audio |
| Skeleton | acceleration |
| depth | radar |
| infrared | wifi signal |
| point cloud1 | |
| event stream |
1 3차원 공간상에 퍼져 있는 여러 포인트(Point)의 집합(set cloud)으로 Lidar 센서와 RGB-D 센서로 수집된 데이터다.
1.1 visual modalities
일반적으로는 visual modalities가 HAR 발전에 큰 영향을 미쳐왔다. HAR의 많은 발전이 RGB Video 또는 images를 기반으로 이루어졌음을 보면 알 수 있다. RGB data는 관측 (surveillance) 또는 추적 (monitoring) 시스템에서 보편적으로 사용되어왔다. RGB 는 기본적으로 세 채널을 가진 ’이미지(들)’이기 때문에 큰 computing resource 를 필요로 하는데 이를 보완하기 위해 사용된 데이터가 skeleton 이다. skeleton data는 인간 관절의 움직임 (trajectory of human body joints) 을 encoding한 데이터로 간명하고 효과적이다. 그러나 물체가 포함되어있거나 장면간 맥락을 고려해야 하는 경우 skeleton data 만으로는 정보를 충분히 얻을 수 없는데 이 때 point cloud 와 depth data를 사용한다. 또한, ’본다’는 행위는 근본적으로 빛에 의존하는데 이 한계를 극복하기 위해 infrared data를 사용하며 event stream 은 움직였을 때를 감지하는 동작 중심 modality다.
정보를 얻고, insight 또는 활용 가능한 부분만 추려내어 새로운 방법론을 창안하고, 기술이 최적화 되었을 때 더 필요한 정보를 얻기 위해 또 다른 modality를 사용하며 다시 불필요한 부분을 제거하는 방식으로 기술이 발전되어왔다.
- 가시영역에서 얻을 수 있는 정보를 얻거나 : RGB
- 인간이 눈으로 보고 이해하는 정보에 집중하여 인간 신체에서 이른바 ROI를 추출해내는 방법을 적용한다: skeleton
- 사람과 환경의 상호작용 또는 시공간적 맥락을 고려하기 위해 3D 구조에서 주요한 정보를 추출하는 작업을 거친다: point cloud, depth data
- 시각에 의존하지 않고 나아가 비가시영역인 적외선 영역에서 정보를 얻음으로써 빛에 의존해야 한다는 visual modalities의 태생적 한계를 극복한다: infrared data
- 불필요한 중복, 또는 정보를 제거하여 HAR에 적합한 데이터를 구축한다: event stream
1.2 non-visual modalities
눈으로 봤을 때 직관적이지 않지만 사람들의 행동을 표현하는 또 다른 방식이다. 직관적이지 않음에도 사용될 수 있는 이유는 특정 상황에서 대상의 개인정보 보호가 필요할 때다. audio 는 시간에 따른 상황 (temporal sequence) 에서 움직임을 인지하기에 적절하며, acceleration 는 fine-grained HAR에 사용된다. 2 3 또한 radar는 물체 뒤의 움직임도 포착할 수 있다.
2 fine-grained HAR : 세분화된 HAR. acceleration data가 이에 사용된다는 내용은 영상의 움직임에서 가속도를 알아내는 방향의 연구를 말하는 것으로 보인다.
3 관련 논문: https://arxiv.org/abs/2211.01342
1.3 Usage of modalities (single vs multi)
single modality and effect of their fusion
살펴본 바와 같이, 각 modality는 서로 다른 강점과 한계를 가지고 있으므로 여러 양식의 데이터들을 합치거나(fusion), 데이터 양식간 ‘transfer of knowledge’4 를 진행하여 정확도와 강건함을 높인다.
4 Transfer learning 은 Transfer Learning과 Knowledge Distillation으로 나뉘는데 서로 다른 도메인에서 지식을 전달하는 방법이 Transfer Learning (fine tuning 필요) 이고, 같은 도메인에서 다른 모델 간 지식 전달이 이루어지는 것을 Knowledge Distillation이라고 하면 ’transfer of knowledge across modalities’는 Transfer Learning을 말하는 것으로 보인다.
나아가 fusion은, 서로 다른 두 개 이상의 데이터에서 각 데이터간 장단점을 상호보완하기 위한 방법론으로 소리 데이터와 시각 데이터를 포함함으로써 단순히 ‘물건을 내려 놓는’ label을 가방을 내려 놓는지, 접시를 내려놓는지 구체적으로 구분할 수 있게 한다.
data modalities and its pros and cons
 |
|---|
2. Single modality
RGB, Skeleton, depth, infrared, point cloud, event stream, audio, acceleration, radar, WiFi will be reviewed
visible Modalities
2.1 RGB
한계와 장점 모두 RGB Data의 특성에서 비롯된다.
- 특성
- 이미지(들) 로 이루어져있다. (\(\because\) video is sequence of images)
- RGB data를 생성하는 카메라는 사람의 눈으로 보는 장면을 재생산하는 것을 목적으로 한다.
- 수집하기 쉽고 상황과 맥락을 반영하고 있는 풍부한 외관 정보가 포함되어있다.
- ‘rich appearance information’
- 폭넓은 분야에 사용될 수 있다.
- visual surveillance: 사람이 한 순간도 놓치지 않고 관찰할 수는 없는데 이를 보완할 수 있다.
- autonomous navigation: 자율주행(ANS)의 일부로써 사람의 개입 없이 정확하게 목적지까지 도달하도록 하는 기술이다.
- sport analysis: 눈으로 쫓기 힘든 순간들을 정밀하게 판독해야 하는 분야이므로 이 또한 ’사람의 눈’을 대신한다.
- 한계
- various of background, viewpoints, scales of humans
- 학습할 수 있는 데이터는 한정적이고, 이를 활용할 수 있는 변수는 너무 많다.
- illumination condition
- 촬영이라는 개념이 갖는 근본적인 한계로, 광원 상태에 따라 결과가 달라질 가능성이 있다.
- high computational cost
- 영상은 이미지의 연속이므로 공간과 시간을 동시에 고려하여 모델링하려면 많은 자원이 요구된다.
- various of background, viewpoints, scales of humans
- modeling methods
- pre-deep learning : handcrafted feature-based approach, 수작업 특징 기반 접근법
- Space-Time Volume-based methods
- Space-Time Interest Point (STIP)
- deep learning : currently mainstream
- backbone model을 무엇으로 사용하느냐에 따라 나뉠 수 있다.
- two-stream CNN based method / multi stream architectures (extension of two stream)
- backbone : 2D CNN
- 시간정보가 포함될 수 밖에 없기 때문에 temporal information, spatial information 모두 고려하는 two-stream 접근이 제안되었다.
- RNN based method
- feature extractor : RNN model with 2D CNNs
- RGB-based model
- 3D CNN based method
- pre-deep learning : handcrafted feature-based approach, 수작업 특징 기반 접근법
2.1.1 Two Stream 2D CNN-Based Methods
two 2D CNN branches taking different input features extracted from RGB video for HAR and the final result is usually obtained through fusion strategy
classical approach
고전적으로 two stream network는 각 network를 병렬적으로 학습시킨 후 결과를 융합 fusion 하여 최종 결과를 추론했다. 예를들어, input이 video이면 video에 내재된 정보들을 크게 1) rgb 프레임들은 공간 네트워크의, 2) multi-frame-based optical flow는 시간 네트워크의 학습 정보가 된다. 각 stream은 아래 특성을 각각 학습한다.
- 모양 특성, appearance feature
- 동작 특성 motion feature
이때 multi-frame-based optical flow: 움직임을 묘사하는 방법이며 주로 짧은 시간 간격을 두고 연속된 이미지들로 구성된다. optical flow는 이미지의 velocity(속도) 를 계산하는데 이 속도는 이미지의 특정 지점이 다음의 어디로 이동할지 예측할 수 있게 한다.
- 주로 video understanding 에서 사용되는 개념으로 보인다.
- acceleration data와 어떻게 다른지 알 필요가 있다: The optical flow is used to perform a prediction of the frame to code
- networks: SpyFlow, PWC-Net; compute pixel-wise motion vectors
overcome limitation
RGB 양식 데이터를 사용함에 있어 주된 문제로 지적되는 점은 ’큰 데이터 용량으로 인한 computing resource 부담과 연산 속도 저하’이므로 연산 속도를 높이기 위해 해상도를 낮추거나, 고해상도 데이터에서 center crop을 하는 기법을 적용했다.
better data representation
모델의 성능은 데이터의 양과 질에 좌우된다. 따라서 더 나은 video representation 에 눈을 돌리게 된다. Wang은 multi-scale video frames, optical flow를 각 CNN stream에 넣어 특성맵 feature map을 추출했고 이에서 trajectories에 중심을 둔 spatio-temporal tubes5 or action tube6를 샘플링했다. 이렇게 한 결과, Fisher Vector representation7과 SVM을 통해 분류했다.
5 Discovering Spatio-Temporal Action Tubes (2018), https://arxiv.org/abs/1811.12248
6 Finding action tubes, https://ieeexplore.ieee.org/document/7298676
7 https://zlthinker.github.io/Fisher-Vector
- 왜 튜브일까? : Finding action tubes (Georgia Gkioxari, 2015) 가 시기상 더 먼저 나온 논문이므로 후자에서 제시된 개념일 것으로 추정된다.
- 후자 논문의 Abstract에서 tube는 “예측된 동작을 연결함으로써 시간일관적으로 객체를 탐지하는” 개념이다.
- tube를 생성하는 과정은 아래와 같다.
- suggest image region : 움직임이 두드러지는 영역을 선택
- CNN을 이용하여 공간적 특징을 추출
- Action tube를 생성


Fig 1. Discovering Spatio-Temporal Action Tubes Fig 2. Finding action tubes; action tube approach
Long term video level information
정보를 mean pooling하거나 누적하여 단일한 움직임이 아닌 움직임의 연속; 좀 더 복잡한 행동을 인식
각 비디오를 세 개의 segment로 나눈 후 two stream network에 입력한 후, 각 segment의점수를 average pooling 을 이용해 융합한다. 또는 segment 점수를 pooling하지 않고 element-wise multiplication으로 특성의 총계를 구한다. 이 때 two stream framework에 의해 샘플링된 외형과 동작 프레임들은 ’하나의 video-level multiplied’를 위해 aggregate 연산되며 이를 action words 라고 칭한다. 8
8 R. Girdhar, D. Ramanan, A. Gupta, J. Sivic, and B. Russell, “Actionvlad: Learning spatio-temporal aggregation for action classification,” in CVPR, 2017.
 |
|---|
Fig 3. 동작들에서 행동과 관계된 action word를 추출한 후 이를 총 망라하는 하나의 분류를 선택하는 과정 |
EXTENSION of two stream CNN based method*
3 stream 으로 확장하는 등, “움직임” 또는 “프레임간 연속성”을 학습시키기 위해 다양한 방법론을 도입했다. 이후 2 stream siamese network (SNN) 로 확장되었는데 이는 동작 발생 전과 동작 후 프레임에서 특징을 추출하는 one shot learning의 일종으로 연속성이 아닌 동작 시작, 전, 후를 구분하여 학습하는 발상의 전환을 꾀한다.
- one shot learning : 소량의 데이터로 학습할 수 있게 하는 방법이 few shot learning이라면 one shot은 그 극한으로 이미지 한장을 학습 데이터로 삼는 방법론이다. 사람은 물체간의 유사성을 학습하는데, 이 유사성은 물체를 배우고 물체간의 유사성을 또 다시 배우는 과정으로 나뉠 수 있다. 다시말해, 물체의 특성을 학습하고 이를 일반화할 줄 아는 능력을 학습시키는 방법이 one/few shot learning이다.
- \(\therefore\) 이미지 자체의 특성을 학습하는 것이 아닌, 이미지간의 유사성을 파악하고 유사도를 파악할 때 쓰는 기법인 ’거리 함수’를 사용한다.
- siamese network
- two stages: verification and generalization 가 포함된다.
- 각각 다른 입력을 동일한 네트워크 인스턴스에 학습시키고, 이는 동일한 데이터셋에서 훈련되어 유사도를 반환한다.
Tackle high computational cost
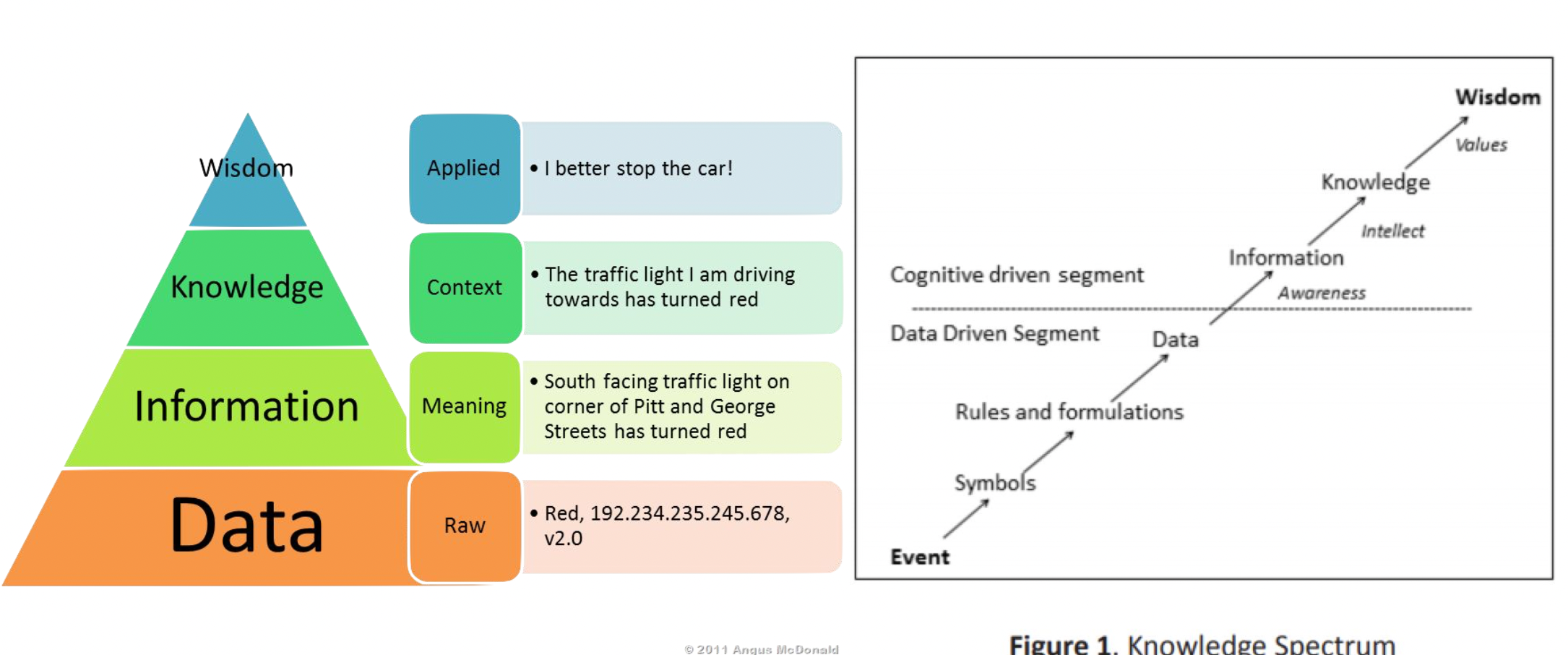
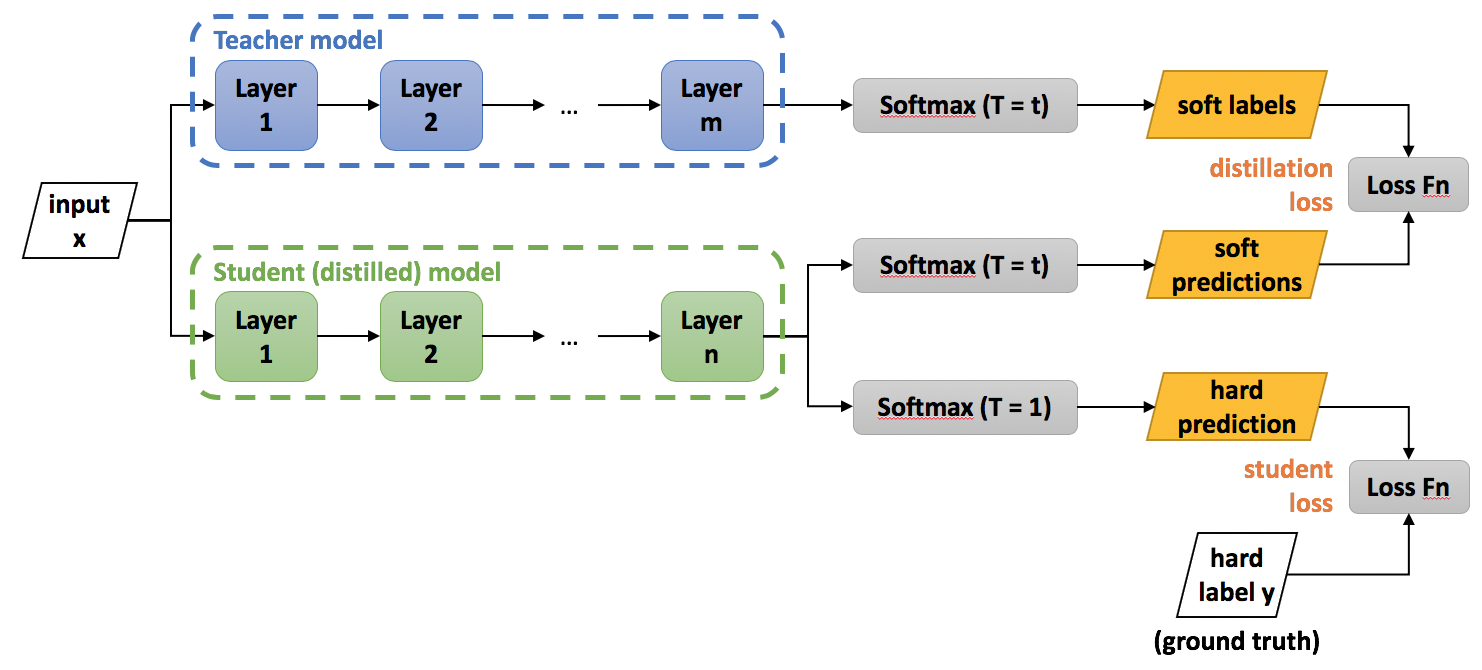
Knowledge distillation 9이 사용된다. “Data 에서 의미를 파악하면 Information 이 되고, Information 에서 문맥을 파악하면 Knowledge 이 되고, Knowledge 를 활용하면 Wisdom 이 된다.” 모델 압축을 위한 절차로, soft label과 hard label을 일치시키는 것이 목적이며 soft label에는 temperature scaling function을 적용하여 확률 분포를 부드럽게 만든다. 예를 들어 feature들의 label이 \([0, 1, 0]^{T}\) 이면 Hard label, \([0.05, 0.75, 0.2]^{T}\) 이면 soft label이다.
9 Distilling the Knowledge in a Neural Network(2015), https://arxiv.org/abs/1503.02531
각 feature들은 서로 다른 특성을 가지고 있지만 공통된 특성 또한 가지고 있기 때문에, 이 공통 요소를 포함하는 class score를 날려버리면 (hard label) 정보가 손실되는 셈이다. 이렇게 정보가 손실되지 않게 Teacher network를 구성하고 Student network가 teacher network에 최대한 가까운 정답을 반환하도록 학습시킨다. 위에서 언급한 temperature는 그 값이 낮을 때 입력값의 출력을 크게 만들어주는 등 필요에 따라 값에 가중치를 둠으로써 Soft label의 이점을 최대화 한다.
| teacher network; optical flow data |
|---|
| ⬇︎ Knowledge Distillation ⬇︎ |
| student network; motion vector |
 |
 |
|---|---|
| Knowledge Spectrum | Distillation Architecture |
In Conclusion
여러개의 stream으로 CNN architecture들을 확장하거나 더 깊게 레이어를 쌓는 등 여러 시도를 해보았으나 수많은 video의 frame 개수를 고려할 때 깊이는 오히려 HAR에 방해가 될 수 있다. 선행 연구를 통해 ’차별화된 특징’을 예측하는 것이 중요함을 파악하게 되었다. 이 외에도, fusion strategy research의 마지막 conv layer에서 공간과 시간 네트워크를 융합하는 방법이 위에서 지적된 컴퓨팅 자원을 절약하면서 (params를 줄이면서) 정확도를 유지하는 효과적인 방법임을 알아냈다.
2.1.2 RNN based
feature extractor 로 CNN을 사용한 hybrid architecture
LSTM based model
Vanilla Recurrent Neural Network의 gradient vanishing 문제로 인해 RNN based solution은 gate 를 포함하는 RNN Architecture를 채택한다. (e.g. LSTM)
 |
|---|
| Fig 5. RGB modality modeling methods (CNN, RNN based) |
물론 ‘이미지’에서 공간적 요소를 빠트릴 수 없기 때문에 특징 추출은 여전히 2D CNN으로 진행하고, 시간요소를 LSTM에서 차용한 구조를 통해 모델링한다. 이를 LRCN (Long Term Recurrent Convolutional Network, Jeff Donahue et al. in 2016) 라고 하며 이는 ’2D CNN; 프레임 단위 RGB feature 추출’ + ’label 생성 LSTM’으로 구성된다.
attention mechanism
multi layer LSTM model 설계 후 다음 프레임에 가중치를 부여한 Attention map 을 재귀적으로 출력함으로써 공간적 특성에 집중할 수 있게 되었다.
recap : main idea of attention; decoder에서 출력 단어를 추론하는 매 순간마다 encoder에서의 전체 문장을 참고한다는 점. 단, ’해당 시점에서 예측에 필요한 부분에 집중(attention)’해서 구한다. \(Attention (Q, K, V) = Attention \ Value\) 로, Query에 대해 모든 Key와의 유사도를 구한 후 이에 관계된 Value에 반영한다. 유사도가 반영된 값, value는 attention value라고도 한다.
- Q : t 시점에서 디코더 셀에서의 은닉상태
- K : keys, ‘모든 시점에서’ 인코더 셀의 은닉 상태
- V : Values, ‘모든 시점에서’ 인코더 셀의 은닉 상태로 각 인코더의 attention 가중치와 은닉상태가 가중합 된 값이다. (a.k.a. context vector)
2.1.3 3D CNN based method
HAR의 공간과 시간을 모두 식별할 수 있다는 강력한 장점이 있으나 많은 양의 훈련 데이터를 요구한다.
지금까지는 모두 2D CNN을 시간과 함께 모델링했다. 그러나 Tran et.al [66]은 raw video data에서 시공간 데이터를 end-to-end 학습하기 위해 3D CNN 모델을 도입한다. 단, 이 경우 클립 수준 (16 frames or so) 에서 사용되는 모델이므로 시간이 길어질수록 temporal 정보가 옅어지는 한계가 있다.
이에, Diba et al.(github, paper)는 3D 필터 및 pooling kernel로 2D 구조였던 DenseNet을 확장한 T3D (Temporal 3D ConvNet) 과 새로운 시간 계층 TTL (Temporal Transition Layer) 을 제안했다.
- 시간에 따라 convolution kernel depth가 달라지도록 모델링 한 것 같다. 3D CNN 모델이 2D 단위에서 학습한 것을 활용하지 않는 것에 착안해 2D와 3D를 함께 쓰는 방식을 채택한 것으로 보인다.
- 그 외에, 시간 범위를 늘린 LTC (Long-term Temporal Convolution) 모델, multi scale ‘temporal-only’ convolution인 Timeception 모델 등이 제안되었다.
- 이는 모두 복잡하거나 긴 작업에서 영상의 길이에 구애받지 않고 인식할 수 있는 강건한 모델을 만들기 위함이다.
2.2 Skeleton
시점 변화에 민감한 pose estimation에서는 motion capture system으로 수집한 데이터셋만 신뢰할 수 있다. (“NTU RGB+D 120: A large-scale benchmark for 3d human activity understanding,” TPAMI, 2020.) 최근의 많은 연구는 NTU Dataset의 depth map, 또는 RGB video를 사용한다.
RGB video만 사용할 경우 옷 또는 신체의 부피를 포함해 RGB data의 문제였던 다양한 변수 (e.g. background, illumination environment) 로부터 상당부 자유로울 수 있다. 초기에는 수작업으로 특징을 추출하여 관절 또는 신체 부위 기반의 방법이 제안되었는데 딥러닝의 발전에 따라 RNN, CNN, GNN, GCN을 적용하게 되었다.
 |
|---|
| Fig 7. Performance of skeleton-based deep learning HAR methods on NTU RGB+D and NTU RGB+D 120 datasets. |
2.3 depth
Depth maps refer to images where the pixel values represent the distance information from a given viewpoint to the points in the scene.
색상, 질감 등의 변화에 강건하며 3차원 상의 정보이므로 신뢰할 수 있는 3D 구조 및 기하학적 정보를 제공한다.
depth map은 왜 필요한가? 3D 데이터를 2D 이미지로 변환하기 위함이다: depth 정보는 특수한 센서를 필요로 하는데, 이는 active sensors (e.g., Time-of-Flight and structured-light-based cameras) and pas- sive sensors (e.g., stereo cameras) 로 나뉜다.
- active sensor는 방사선을 물체에 방출하여 반사되는 에너지를 측정하여 깊이정보를 얻는, 말그대로 능동적인 행동에 의해 발생하는 정보를 수집하는 센서다. Kinect, RealSense3D 등의 특수한 장치를 포함하는 센서가 포함된다.
- passive sensor는 물체가 방출하거나 반사하는 자연적인 에너지 를 말한다. 수동센서의 예인 stereo camera는 인간의 양안을 시뮬레이션 하는 카메라로 are recovered by seek- ing image point correspondences between stereo pairs 한다.
둘을 비교했을 때, passive depth map generation은 RGB 이미지 사이에서 깊이를 연산해내는 과정이 포함되므로 계산 비용이 많이 들 뿐 아니라 질감이 없거나 반복 패턴이 있는; view point에 따라 크게 달라지지 않는 대상에는 효과를 보이지 않을 수 있다. 따라서 대부분의 연구는 active sensor를 이용한 depth map에 초점을 맞추고 있다. (“only a few works used depth maps captured by stereo cameras”)
datasets and methods
데이터셋으로는 Deep Learning methods가 도래하기 전까지 사용했던 hand-crafted Depth Motion Map (DMM) features가 있다. 딥러닝 프레임워크도 이 DMM을 활용하는데, weighted hierarchial DMMs 이 제안되었다. 그러나 기존의 DMMs가 구체적인 시간정보를 포착하지 못하는 한계를 직면하자 Wang et.al 은 dynamic images at the body, body part, joint level 총 세가지를 짝지은 depth sequences 를 CNNs에 먹이는 방식을 제안했다.
depth modality의 성능은 아래의 발견에 힘입어 크게 성장했다.
- depth maps including dynamic (depth images)
- dynamic depth normal images
- dynamic depth motion normal images
발전을 위해 제안된 아이디어는 view invarient 을 이용한 방법론들이 다수인데, 다른 시각에서 본 이미지들을 high-level space로 옮김으로써 입체감을 부여하고 (Rahmani et al. [9]) CNN 모델이 human pose model과 Fourier Temporal Pyramids를 학습하게 하여 시점에 따른 행동 변화를 학습하게 하는 방식이 있다.
estimate without depth sensor
Newer methods can directly estimate depth by minimizing the regression loss, or by learning to generate a novel view from a sequence.
그러나 depth 정보를 추정해낼 수 있는 방법 또한 있다. depth estimation 기술이 이미 존재하고 Zhu and Newsam [224] 는 depth estimation을 이용해 RGB video에서 depth 을 추출해낸 바 있다. 10 가장 많이 사용되는 벤치마크는 KITTI와 NYUv2이며 일반적으로 RMS 메트릭에 따라 평가된다. 해당 기술의 Subtask로는 Monocular Depth Estimation, Stereo Depth Estimation 등이 있다.
10 https://paperswithcode.com/task/depth-estimation
2022 큰 주목을 받았던 diffusion model 또한 depth estimation을 사용하고 있다. multi-view 이미지들에서 차이점이 되는 point들을 찾고, 이 차이를 “splatting and diffusion”하여 depth map을 생성한다. 11

generating diffusion map by splatting and diffusion differences of Multi-View images
11 differentiable diffusion for dense depth estimation from multi-view images (CVPR, 2021)
limitation
그러나 일반적으로 depth information은 외형정보가 부족하므로 다른 data modality와 융합하여 사용된다. - section 3 에서 더 살펴볼 수 있으나, 본 포스트에서는 single modality까지만 다루겠다.
2.4 infrared (IR)
Infrared radiation is emitted from all surfaces that have a temperature above 0 K (−273.15 °C) and the strength of emitted radiation depends on the surface temperature higher temperatures have greater radiant energy 12
12 sciencedirect/infrared-radiation, https://www.sciencedirect.com/topics/physics-and-astronomy/infrared-radiation
주변광에 의지하지 않아도 되므로 야간 HAR에 적합하다. depth sensor와 마찬가지로 반사광선을 활용하여 물체를 인식하는데, 적외선을 내보내는 센서가 active sensor라면 대상에서 방출되는 광선 (열 에너지 등) 을 인식하는 방법은 passive sensor를 이용한 인식이다.
methods
신호에서 minimum하게 구분할 수 있는 간격으로 탐지하기 위해 받아들이는게 신호라고 할 때 서로 다른 신호의 간격이 얼마나 가까이까지 구분해낼 수 있는가를 해상도라고 말한다. 즉, 실제로 서로 다른걸 다르다고 말할 수 있는 거리가 해상도다. 해상도가 높으면 같은 이미지도 높은 픽셀로 표현할 수 있다. 극히 낮은 해상도의 row resolution thermal images에서 먼저 사람의 무게중심을 기반으로 사람 부분만 추출하고, 다음으로 cropped sequences들과 frame간 차이를 LSTM기반의 CNN에 입력해 시공간 정보를 담은 모델을 생성할 수 있다. (Kawashima et.al, 2017)13
13 Action recognition from extremely low-resolution thermal image sequence
- 왜 굳이 저해상도 이미지를 사용하는가?
- 적외선 이미지(InfraRed)는 해상도가 rgb 이미지보다 훨씬 낮다.
- 적외선 방사선 검출기의 단점이자 한계, 해상도를 개선한 센서도 있다: High Resolution infrared Radiation Sounder14
- 저해상도면 저해상도지 초저해상도 이미지를 굳이 사용하는 이유는?
- 절대적인 위치 정보인 픽셀값이 아니라 상대적인 위치에 집중할 것이니 해상도 자체가 크게 의미있지 않다. 15
- 초저해상도 이미지를 사용할 수 있는 이유는 다음과 같이 정리된다
- RGB high resolution image 도 human body edge를 명확하게 연산하기는 어려우며 pixel values들은 사람의 움직임, 센서와의 거리 등에 크게 영향을 받는다.
- 따라서 high resolution image가 집중하는 human body edge가 연산해내기 어려운 특성이라면 아예 이를 제외하고 다른 부분에 초점을 맞추겠다는 선언으로 보인다.
- 대신 대략적인 범위를 알 수 있으니 결국 얼만큼 움직이는지만 감지해내면 되고, 그 움직임은 pixel 값으로 표현되니 optical image 를 대신할 수 있다.
- 이는 ’초’저해상도 이미지로도 가능하기 때문에 연산량 등의 이점을 얻기 위해 해상도를 최대한 내린 것으로 유추된다.
14 HIRS
15 Action recognition from extremely low-resolution thermal image sequence.(2017)
 |
 |
|---|---|
| Figure 3. Example of images captured at night-time | Figure 4. Example of a thermal image sequence |
thermal images와 thermal sequence의 차이는?
- 이미지간 차이를 추출해낸 결과다. 이후 열화상 비디오들에서 학습된 시공간 정보를 동시에 학습하기 위해 3D CNN을 적용한 Shah et al의 연구가 이어졌고, Meglouli et al는 raw thermal images를 사용하는 대신 raw thermal sequences를 3D CNN에 적용하여 optical flow information를 연산해냈다.
 |
 |
|---|---|
| Example of a thermal image sequence16 | Example of RGB and InfRared17 |
16 Action Recognition from Extremely Low-Resolution Thermal Image Sequence
17 IR pair images in real maritime dataset
2.5 Point Cloud
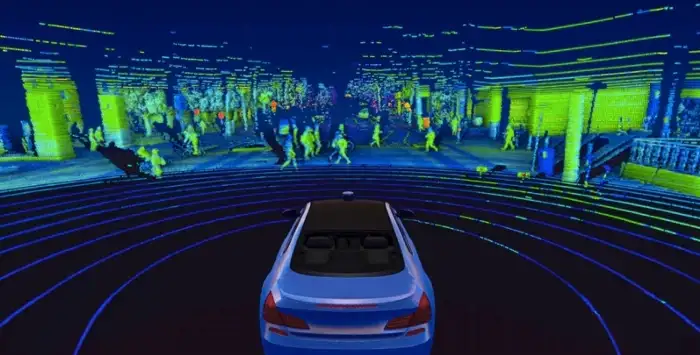
Point cloud data is composed of a numerous collection of points that represent the spatial distribution and surface characteristics of the target under a spatial reference system.
시공간보다는 2D와 3D 모두 풍부한 정보를 얻을 수 있는 데이터 양식으로 2차원에서는 실루엣을, 3차원에서는 대상의 기하학적 정보를 포함하기 때문에 3D HAR에서 확고한 입지를 다지고 있다. 해당 정보를 얻기 위한 방법은 두가지가 있는데 하나는 3D sensor (cf. LiDar, Kinect) 를 사용하는 것이고 다른 하나는 이미지를 기반으로 한 3차원 재구성 (image based 3D reconstruction) 을 수행하는 것이다.
 |
|---|
| Fig 1. lidar point cloud |
Using point cloud sequence by Voxel
또한 딥러닝의 발전으로 딥러닝 방법론이 주목받았고, 일반적으로 더 나은 성능을 보였다. 2020년 CVPR에서 “3dv: 3d dynamic voxel for action recognition in depth video,” 발표되어 raw point cloud sequence를 일반적으로 사용할 수 있는 3D 화소 집합 (voxel sets) 으로 변환한 바 있다.
- voxel : 입체 화상을 구성하는 3D 화소로 volume element를 말한다. 데이터 포인트로 구성되는데 이는 하나 또는 여러개의 데이터 조각으로 구성된다. (e.g. 불투명도, 색상 …) 따라서 Vector (or Tensor) 데이터로 구성되며 다양한 속성을 표현할 수 있다. (e.g. CT에서 재료의 불투명도를 부여하는 Hounsfield scale: 방사선의 밀도를 표현)
- pixel (picture + element): raster image를 구성하는 가장 작은 단위 또는 display에서 접근 가능한 모든 점들의 집합을 말하며 대부분 digital display 에서 표현되는 그래픽들의 가장 작은 단위로 사용된다.
- voxel (volume + element): 3D Computer graphic에서 3차원 상의 일반 격자(regular grid)를 나타내기 위한 단위로, 고유한 state parameter를 가지며 모델 객체에 종속된다. 18
- regular grid? : grid는 regular grid와 irregular grid로 구분되는데 일반 격자는 테셀레이션(tesselation)의 n차원 유클리디안 공간으로 규칙적인 간격을 가진다.
- tesselation? : 테셀레이션은 computer graphic 용어로 장면의 객체를 렌더링하기에 적합하도록 나타내는 다각형 데이터 집합 또는 vertex sets 이다.*
- texel (texture + element): texture map의 기본단위로, 이미지를 픽셀로 표현하는 것 처럼 배열을 texture 공간에 나타내어 질감을 표현한다.
- resel (resolution + element ): 실제 공간 해상도에서 이미지 또는 부피데이터셋이 차지하는 비율을 나타낸다. resels per pixel, resels per voxel 등으로 표현한다.
18 어쩔 수 없이 wikipedia Voxel 결과
이렇듯 voxel에는 다양한 속성을 표현할 수 있으므로 voxel sets 을 3D action information으로 인코딩할 수 있다. 이러한 추상화 과정을 통해 학습한 모델이 PointNet++다.
물론, point cloud를 voxel로 변환하는 과정에서 다량의 양자화 오차(quantization errors)19가 발생하여 효력면에서 충분히 효과적이지 않은데 이를 해결하기 위해 제안된 모델이 MeteorNet이다. 해당 모델은 여러 프레임의 point cloud들을 local 특성으로 합산하는데 이 때 spatio-temporal neighboring point 들을 사용한다. 다시 말해, 모든 point cloud를 voxel로 변환할 때 유실되는 값이 많으므로 국소 범위에서 관계가 있을 것으로 추정되는 주변 값을 변환하고, 또 변환하여 오차를 줄이는 방식을 채용한 셈이다.
19 ADC (Analog to Digital Converter) 에서 입력 아날로그 신호가 출력 디지털 신호로 변환될 때 유실되는 값이다.
이와 반대로 점의 공간적 불규칙성이 정보값에 혼란을 줄 것을 우려한 PSTNet은 시공간 정보를 분리하기도 했다.
Modeling
이렇게 재구성된 Point Cloud로 수행해야하는 바는 다른 modality와 동일하게, 시공간을 동시에 고려고 그 특성을 파악하는 작업이다. 3차원 공간의 정보의 누수를 막고 voxel sets을 구해낸 후의 연구는 시간을 모델링하는데 초점을 맞추는데 이는 여타 방법론과 유사하다. RNN 기반의 모델인 LSTM을 적용한다. 눈여겨 볼 점은 4D CNN이 도입되었다는 점인데, 이는 LSTM 도입의 연장선으로 이미 3차원인 공간 모델링에 시간 차원을 추가하는 방식이다. 20
20 self-supervised modeling이 상대적으로 자주 언급되는데 point cloud 특성 때문인지 확인이 필요하다.